
Shaoxiang Wang
I am a researcher in the Augmented Reality department at German Research Center for AI (DFKI) in Germany, under the supervision of Alain Pagani and Didier Stricker. My research topic is 3D vision and reconstruction. Feel free to reach out if you’re interested in my concurrent research or just want to have a casual chat! :D
I received my Master’s degree in Mechatronics from the Karlsruhe Institute of Technology (KIT), during which I conducted a 6-month thesis project in efficient computer vision at BMW Group with Lukas Frickenstein, under the supervision of Jürgen Becker at KIT and Walter Stechele at TU Munich. Prior to KIT, I obtained a Bachelor’s degree in Mechatronics from Harbin Institute of Technology (HIT).
News
- [May 2026] Outstanding Reviewer at CVPR 2026 .
- [May 2026] Inpaint360GS was invited to a poster session in SPAR-3D workshop at CVPR 2026.
- [April 2026] One paper got accepted in SIGGRAPH 2026.
- [February 2026] One paper got accepted in CVPR 2026.
- [December 2025] Two papers got accepted in WACV 2026.
- [December 2024] One paper got accepted in WACV 2025.
- [February 2024] One paper got accepted in CVPR 2024.
Publications

EgoForce: Forearm-Guided Camera-Space 3D Hand Pose from a Monocular Egocentric Camera
SIGGRAPH 2026
Monocular Absolute Camera-Space 3D Hand Pose and Shape Reconstruction Across Camera Models.
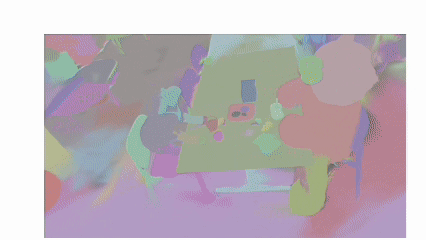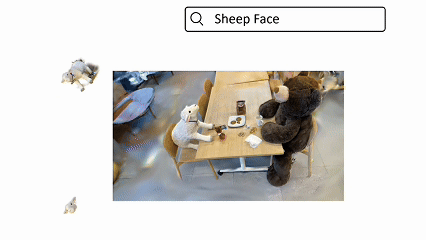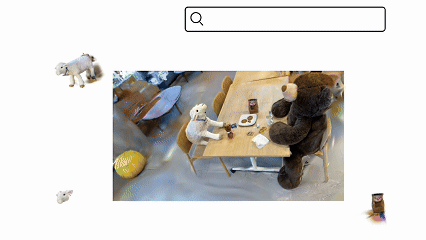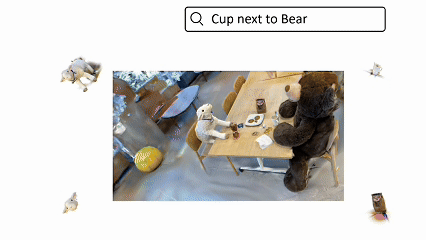
ReLaGS: Relational Language Gaussian Splatting
Shaoxiang Wang, Alain Pagani, Didier Stricker
CVPR 2026
A platform for open-vocabulary 3D reasoning with hierarchical semantics and relational scene graphs.

Inpaint360GS: Efficient Object-Aware 3D Inpainting via Gaussian Splatting for 360° Scenes
Shaoxiang Wang, Shihong Zhang, Christen Millerdurai, Didier Stricker, Alain Pagani
CVPR 2026 Workshop, WACV 2026
We enable multi-object removal and consistent 360° scene completion for your scene!
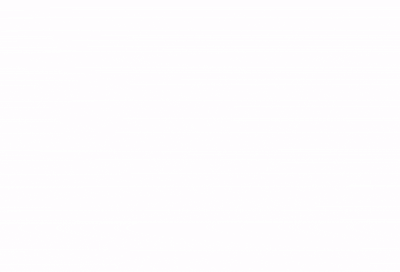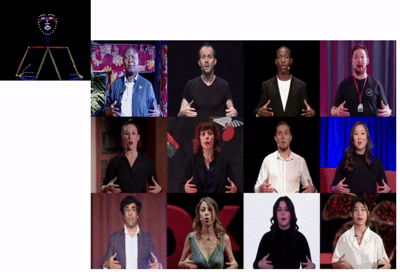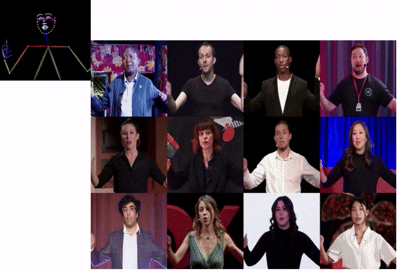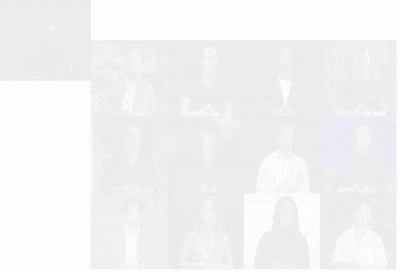
TalkingPose: Efficient Face and Gesture Animation with Feedback-guided Diffusion Model
Alireza Javanmardi, Tewodros Amberbir Habtegebrial, Pragati Jaiswal, Christen Millerdurai, Shaoxiang Wang, Alain Pagani, Didier Stricker
WACV 2026
Achieve temporally consistent long-form animation via feedback-driven diffusion.

Uni-SLAM: Uncertainty-Aware Neural Implicit SLAM for Real-Time Dense Indoor Scene Reconstruction
Shaoxiang Wang, Yaxu Xie, Chun-Peng Chang, Christen Millerdurai, Alain Pagani, Didier Stricker
WACV 2025
Reweight supervision with predictive uncertainty and adapt mapping to achieve accurate real-time indoor reconstruction.

MiKASA: Multi-Key-Anchor & Scene-Aware Transformer for 3D Visual Grounding
Chun-Peng Chang, Shaoxiang Wang, Alain Pagani, Didier Stricker
CVPR 2024
We introduce multi-key-anchor attention to better capture spatial relationships.